Selected Projects
I enjoy making things. Here are a selection of projects that I have worked on over the years.



Apps I’ve built
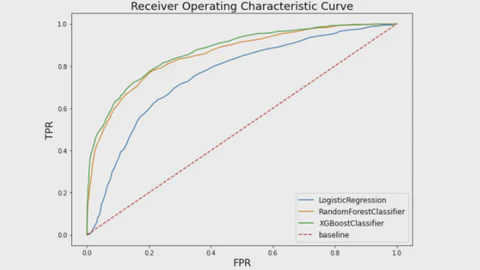
Data Science Projects
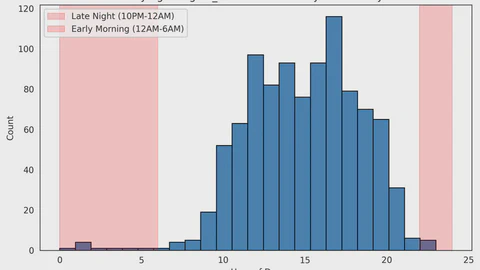



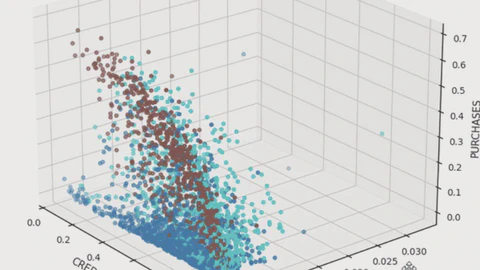
Unsupervised ML Projects
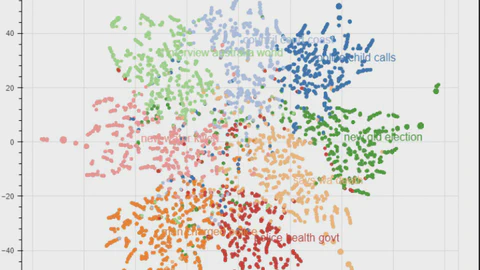
Computer Vision Projects
I enjoy making things. Here are a selection of projects that I have worked on over the years.



